To achieve horizontal scaling, it is important to distribute requests and data efficiently and evenly across servers. Consistent hashing allows us to distribute data across nodes in such a way that minimizes the need for reorganization when nodes are added or removed. This makes the system easier to scale up or scale down.
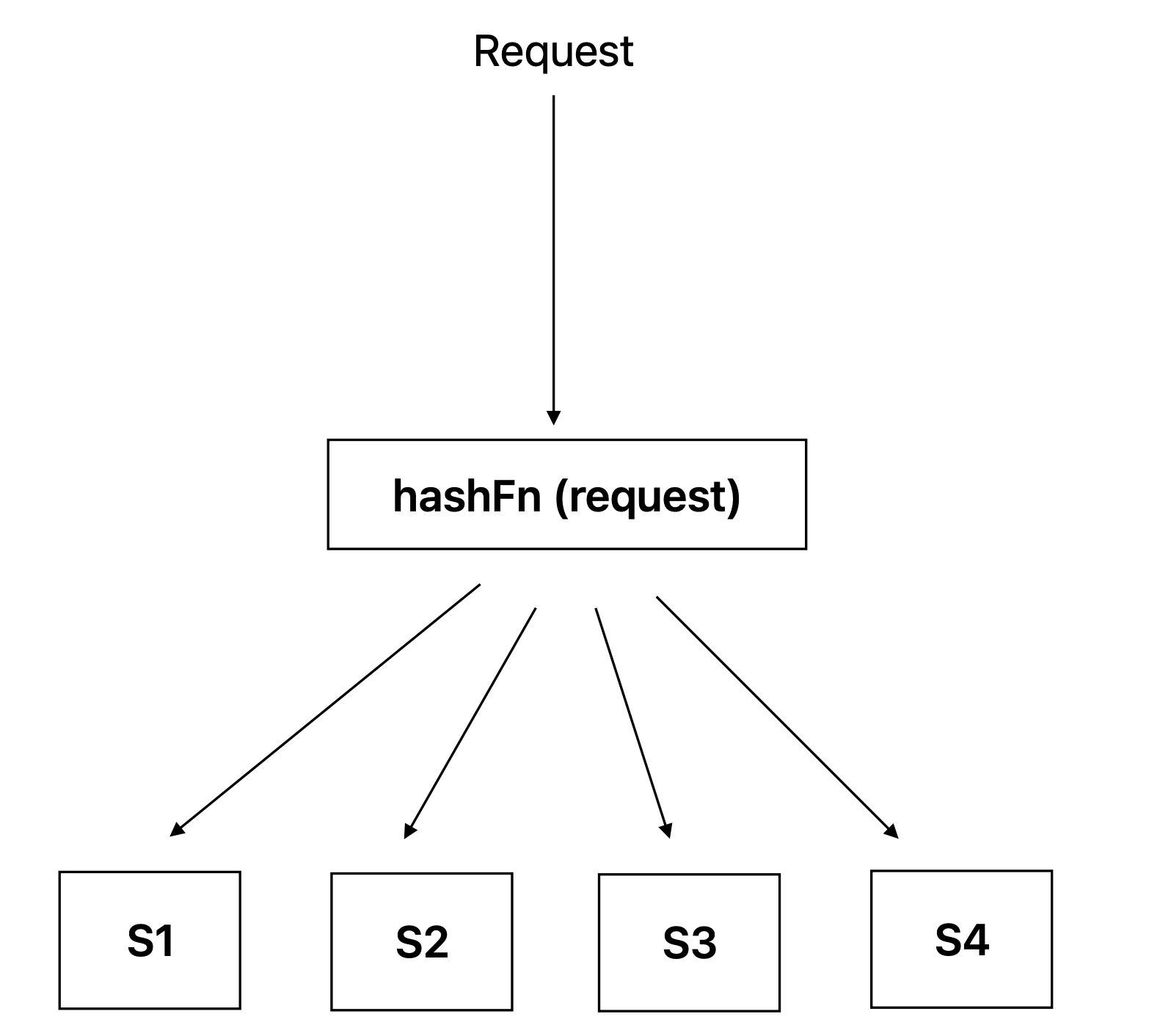
The Problem
Let’s suppose we have a distributed cache system with server nodes S1, S2, S3, and S4. A hash function key = hash(request)%N is used to distribute any incoming request to these servers. If any server goes down, the hash has to be recalculated because the total number of nodes has changed. The hash function would then return a different node for the read requests, which could lead to many cache misses and the need to remap the data.
Similar to the case when a server goes down, when a new server is added to the distributed cache system, the hash function also has to be recalculated. This is because the total number of nodes has changed. The hash function would then return a different node for some of the existing requests, which could lead to cache misses and the need to remap the data.
Consistent Hashing
Consistent hashing is a technique for distributing data across a set of nodes in a way that minimizes the need to remap the data when nodes are added or removed. The nodes are placed on a virtual ring, and each node is assigned a range of keys. When a new data object is added, it is hashed to a location on the ring. The node that covers this location is responsible for storing the data object.
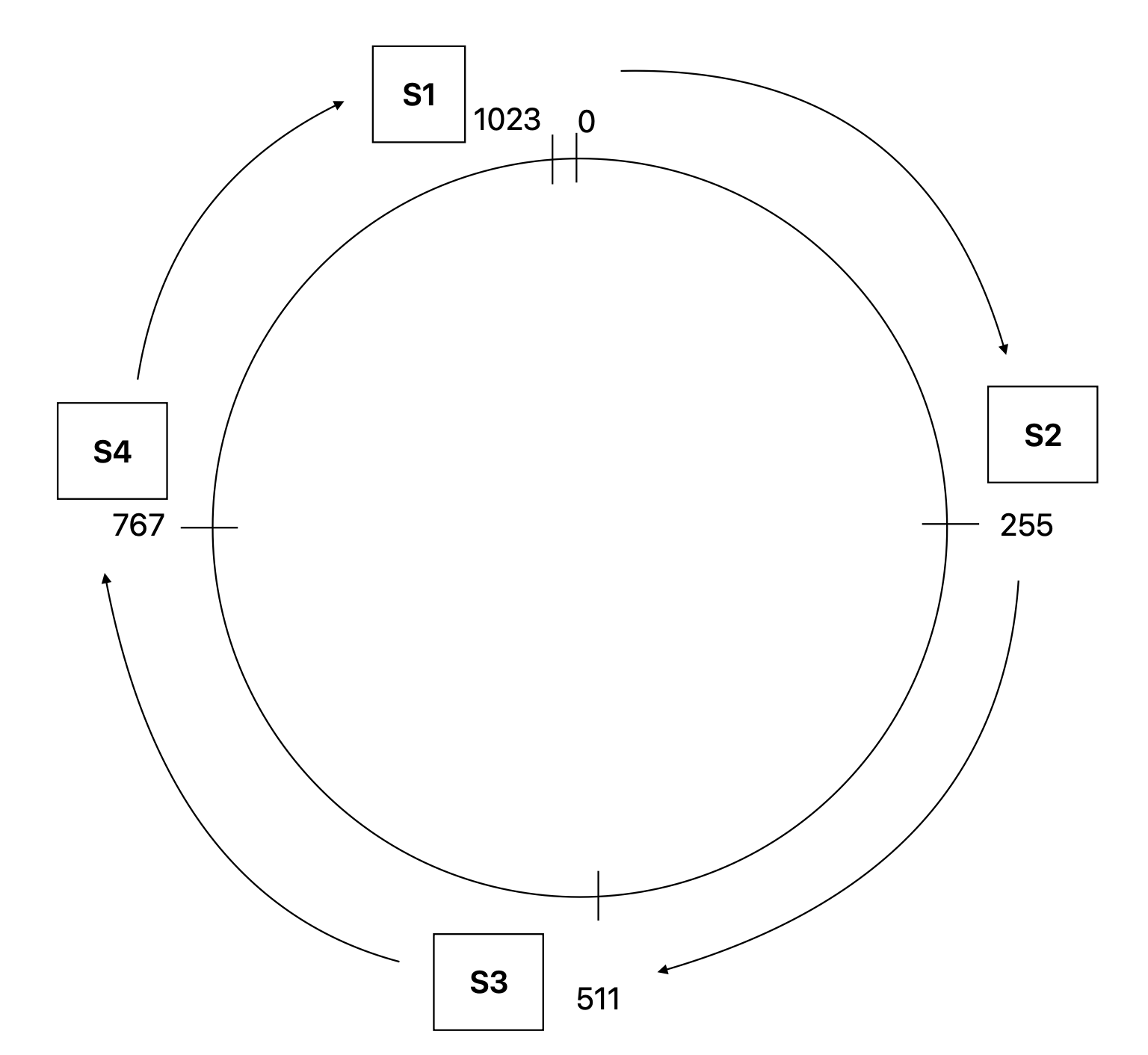
Suppose in this case we have 1024 positions [0, 1024) on the ring, we have a hash function key = hash (request) % 1024 to assign data objects to these positions.
Each server will cover a range of the positions. In this example following are the position ranges the server covers:
- S2 -> [0, 255)
- S3 -> [255, 511)
- S4 -> [511, 767)
- S1 -> [767, 1024)
Now the request data objects are mapped to the position using the same hash function. Let’s suppose the requests R0 to R9 are distributed on the ring as shown in the diagram.
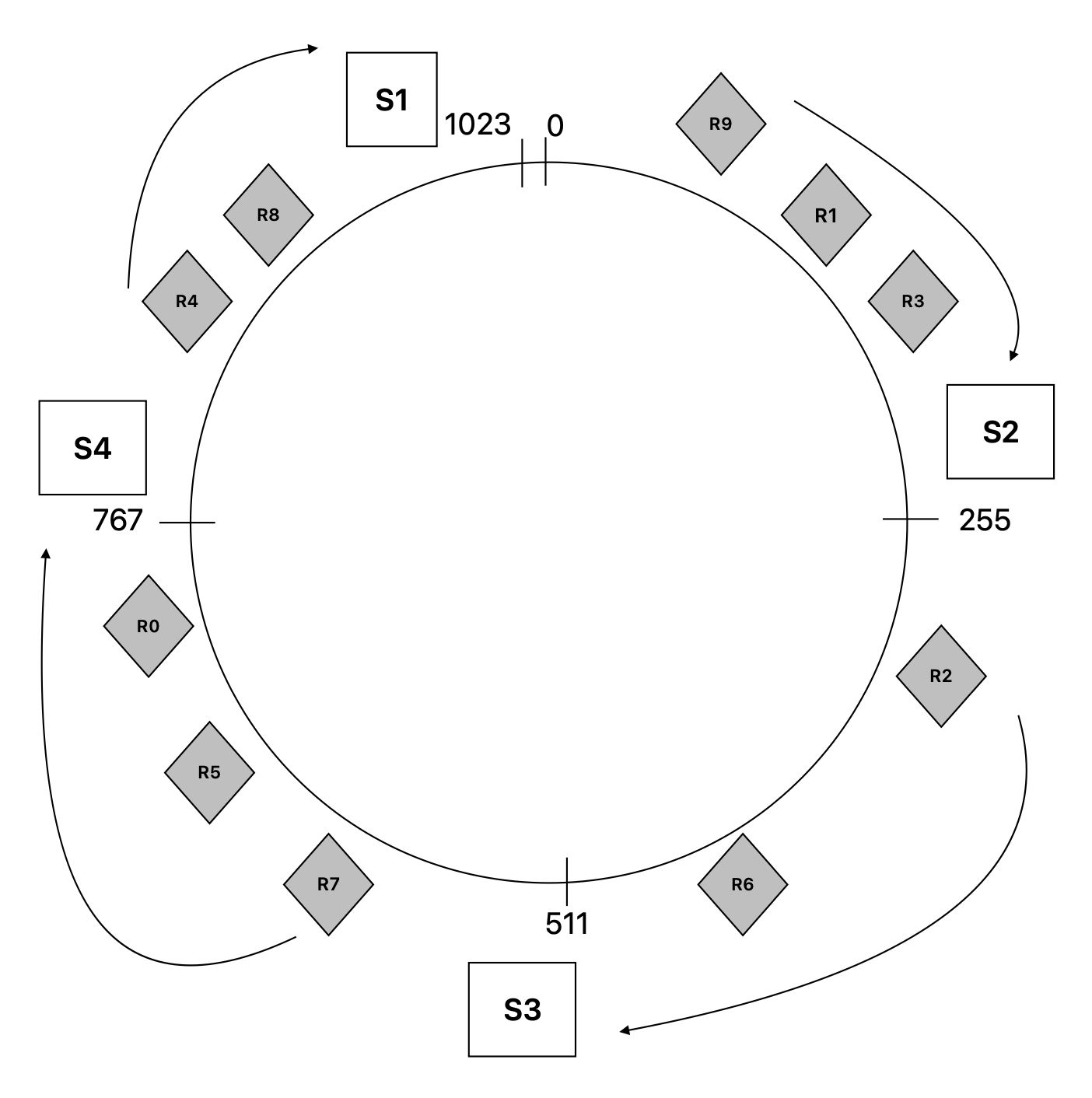
- S2 -> R1, R3, R9
- S3 -> R2, R6
- S4 -> R0, R5, R7
- S1 -> R4, R8
To write a data object to cache:
- Find the hashed key using
key = hash (request) % 1024and place the object in the node in which range the key falls. If the key falls in range (255, 511] place the node in S3.
To read a data object from cache:
- Find the hashed key, and find the node which covers the key position. Read the data object from this node.
On Node Removal
If a node S2 goes down, only the keys that were mapped to S2 needs to be re-mapped, any other mappings for data objects is not impacted. In this scenario the keys R9, R1, R3 will be re-mapped to the next available server in the ring which is S3.
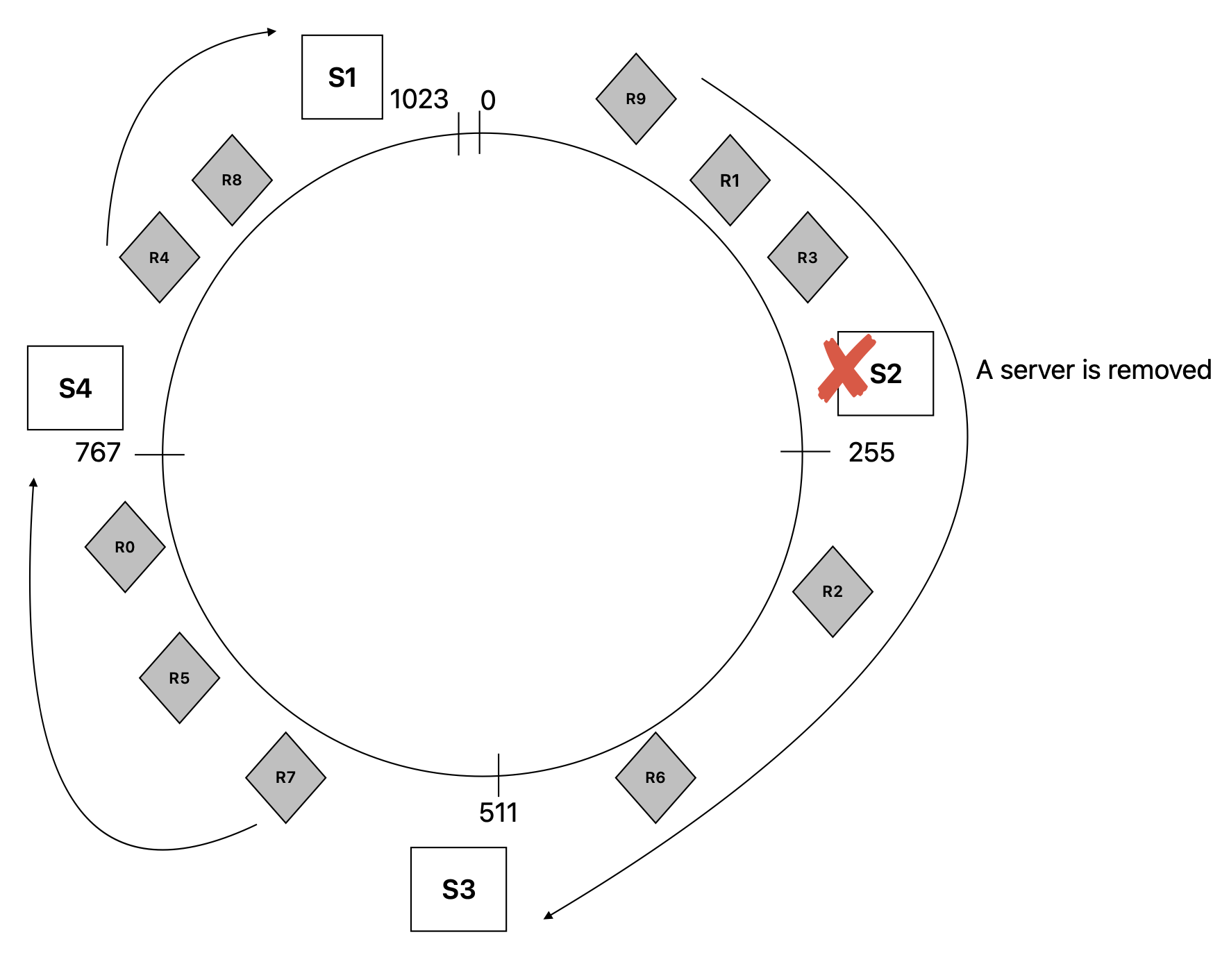
On Node addition
If a node S5 is added to the ring, the keys in [255, 383) will be mapped to S5, all other keys stays with the mapped nodes that they are assigned.
In this scenario R2 is mapped to S5 and now only R6 is mapped to S3
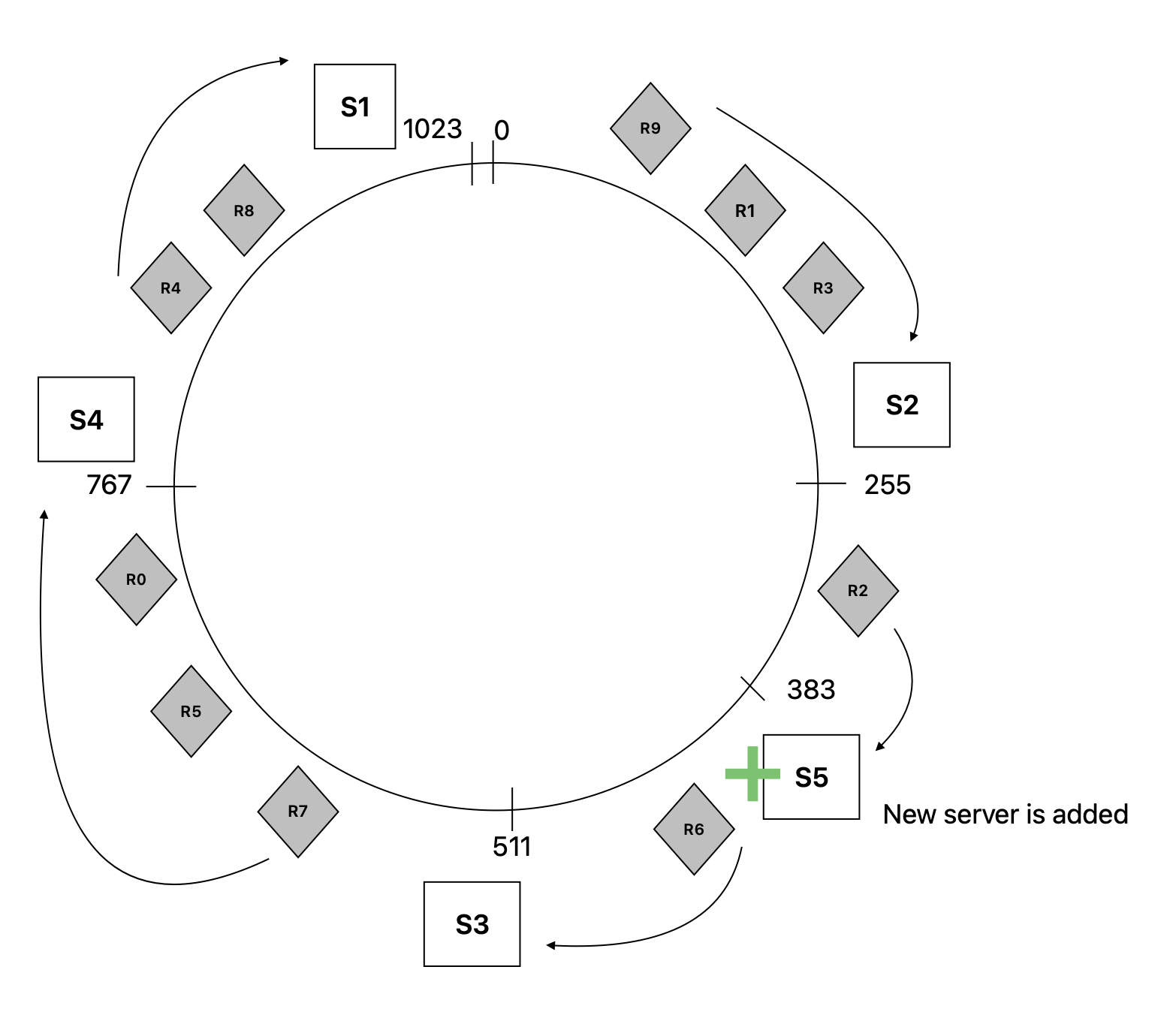
Thus consistent hashsing minimizes the need to re-calculate the hash function for the keys again.
Replication
There is a chance that nodes are not uniformly distributed on the consistent hash ring. The nodes that receive a huge amount of traffic could be overloaded. To ensure uniform distribution of keys among the nodes the nodes are assigned to multiple positions called vnodes or virtual nodes on the hash ring. The data objects can also be replicated onto the adjacent nodes to minimize the data movement when a node crashes or when a node is added to the hash ring.
 Each node S1, S2, S3, S4 is place on multiple position ranges. This helps in more uniform allocation of the data objects across the nodes. It improves load balancing and prevents overloading.
Each node S1, S2, S3, S4 is place on multiple position ranges. This helps in more uniform allocation of the data objects across the nodes. It improves load balancing and prevents overloading.